Playwright 使用教程
Playwright是微软开源的浏览器自动化工具, 支持多浏览器引擎, 提供Python、JavaScript等多语言API. 它通过真实浏览器渲染页面获取数据, 操作接近真实用户, 在数据采集方面可以有效规避反爬机制. 下面我将介绍如何使用这一工具.
- 官方文档: https://playwright.dev
- 官方仓库: https://github.com/microsoft/playwright 80K+ 个 star
什么是 Playwright?
- Web自动化测试工具, 也可以用来作为爬虫工具
- 通过真实浏览器渲染页面后获取数据, 对比通过 API 调用获取数据的方式速度会慢点, 但是简单粗暴, 接近真实用户浏览网页, 较难被反爬针对
工具对比
- Selenium: 基于 Webdriver, 需要中间层转发, 性能较差. 驱动安装麻烦
- Puppeteer: 谷歌出品, 基于Chrome DevTools Protocol(CDP), 性能高. 针对 Chrome 浏览器, 语言支持Javascript
- Playwright: 微软出品, Puppeteer 增强版, 接口与 Puppeteer 几乎一样. 社区活跃文档质量高, 容易上手, 支持多浏览器, 支持多语言(Javascript,Python,Java,C#), 自动管理浏览器安装, 支持Docker部署.
前置准备
test和lib模式
Playwright 支持两种代码模式, test 和lib 模式, test 模式对于测试方面会更加方便强大, 而我们用于爬虫更适合使用 lib 模式
安装
安装 Python 库
pip install playwright
安装浏览器
playwright install
交互模式(REPL)
Python 是解释型语言, 它不需要把整个文件代码编译后才能执行, 可以写一行代码执行一行, 这在开发阶段提供了极大的便利
在命令行输入 python 进入交互界面, 然后就可以一行一行输入代码
from playwright.sync_api import sync_playwright
playwright = sync_playwright().start()
browser = playwright.chromium.launch()
page = browser.new_page()
page.goto("https://playwright.dev/")
page.screenshot(path="example.png")
browser.close()
playwright.stop()
同步和异步
- Python 异步编程
- 异步函数需要在
def前加async - 每次调用异步函数需要在前面加
await main函数需要放在asyncio.run()里执行
- 异步函数需要在
- 可以开发阶段先在交互模式用同步代码边调试边写, 待验证没问题了改成异步代码
上面的代码在异步模式代码如下
import asyncio
from playwright.async_api import async_playwright, Playwright
async def run(playwright: Playwright):
chromium = playwright.chromium # or "firefox" or "webkit".
browser = await chromium.launch()
page = await browser.new_page()
await page.goto("http://example.com")
# other actions...
await browser.close()
async def main():
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())
with 和 start
Python 的 with 语句可以自动管理资源的回收, 建议代码使用 with 语句, 交互模式使用 start()
# 用 with
with sync_playwright() as playwright:
run(playwright)
# 用 start
playwright = sync_playwright().start()
run(playwright)
playwright.stop() # 需要主动调用资源回收
类型注解
Python 是动态类型语言, 对象的类型在运行时才确定, 在写代码阶段, 编辑器可能因为没有足够的类型信息而无法进行类型补全, 如果把类型注解补上, 编辑器就能知道对象什么类型, 从而进行智能补全
async def run(playwright: Playwright):
Python 异常
Playwright 有些操作会抛出异常, 在 Python 中异常要用 try ... except 捕获, 不然会程序终止退出
try:
...
except Exception as e: # except Exception as e: 捕获特定异常
...
finally: # 可不需要
...
第一个代码
from playwright.sync_api import sync_playwright
playwright = sync_playwright().start()
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://example.com")
page.locator('p').all_inner_texts()
page.locator('a').click()
context.close()
browser.close()
playwright.stop()
Playwright
根对象, 使用 with 语句不用调用 stop() 方法
# 异步使用 with
async with async_playwright() as playwright
# 同步使用 start()
playwright = sync_playwright().start()
...
playwright.stop()
BrowserType
对应一个浏览器类型, 通过 Playwright 对象的属性获得
chromium = playwright.chromium
Browser
- 对应一个浏览器实例
- 通过
BrowserType对象的launch()方法创建Browser对象 launch()方法可以带上参数, 默认浏览器以无头模式启动, 在开发时可以设置参数为headless=False让浏览器可见, 生产爬取时需要去掉
browser = await chromium.launch(headless=False)
记得调用 close() 方法回收资源
await browser.close()
BrowserContext
context 的设计提供了一种隔离浏览器会话的机制, 不同的 context 不会共享 Cookies 和缓存, Browser 对象提供 new_context() 方法创建 BrowserContext 对象
context = await browser.new_context()
同样需要记得调用 close() 方法回收资源
await context.close()
一个 Browser 对象可以创建多个 BrowserContext 对象
context1 = await browser.new_context()
context2 = await browser.new_context()
Page
- 对应一个浏览器标签页
Page对象可以通过BrowserContext对象的new_page()方法创建, 也可以直接通过Browser对象的new_page()方法创建(自动在内部创建新的BrowserContext)
使用 goto() 方法请求URL
page.goto("https://example.com")
有时为了防止代码执行完浏览器直接关闭, 可以使用 pause() 方法暂停页面(需要设置参数headless=False)
await page.pause()
Locator
Locator 对象代表 Page 被选中的节点元素, Page 对象提供多种方法获取 Locator, 如 get_by_...(), query_selector() 方法, 推荐统一用 locator() 方法
page.locator('#id') # 根据id选择
page.locator('.class') # 根据class选择
page.locator('h1') # 根据元素类型选择
选中元素后可以像人工操作一样任意操作, Locator 提供了这些方法
获取文本
建议用 inner_text() 方法
# 获取所有可见文本
texts = await page.get_by_role("link").all_inner_texts()
# 获取所有文本
texts = await page.get_by_role("link").all_text_contents()
# 获取所有文本(所有子元素拼在一起)
text = await page.get_by_role("link").inner_text()
文本输入 fill()
await page.get_by_role("textbox").fill("Peter")
鼠标点击 click()
# 单击
await page.get_by_role("button").click()
# 双击
await page.get_by_role("button").dblclick()
通过 Mouse 对象
await page.mouse.down()
await page.mouse.move(0, 100)
await page.mouse.up()
await page.mouse.wheel(0, 10) # 滚动
下拉框选择 select_option()
await element.select_option("blue")
# 选中多个
await element.select_option(value=["red", "green", "blue"])
键盘输入 press()
await page.get_by_text("Submit").press("Enter")
通过 Keyboard 对象
# 输入单个字符
await page.keyboard.press("a")
# 输入多个字符
await page.keyboard.type("Hello")
# 按下某个键
await page.keyboard.down("Shift")
# 放开某个键
await page.keyboard.up("Shift")
文件上传 set_input_files()
await page.get_by_label("Upload file").set_input_files('myfile.pdf')
拖拽元素 drag_to()
await page.locator("#item-to-be-dragged").drag_to(page.locator("#item-to-drop-at"))
滚动
点击滚动按钮自动滚动
await page.get_by_role("button").click()
手动滚动
await page.get_by_text("Footer text").scroll_into_view_if_needed()
用鼠标滚动
await page.get_by_test_id("scrolling-container").hover()
await page.mouse.wheel(0, 10)
用 Javascript 脚本
await page.get_by_test_id("scrolling-container").evaluate("e => e.scrollTop += 100")
元素选择原则
优先使用 ID 选择器
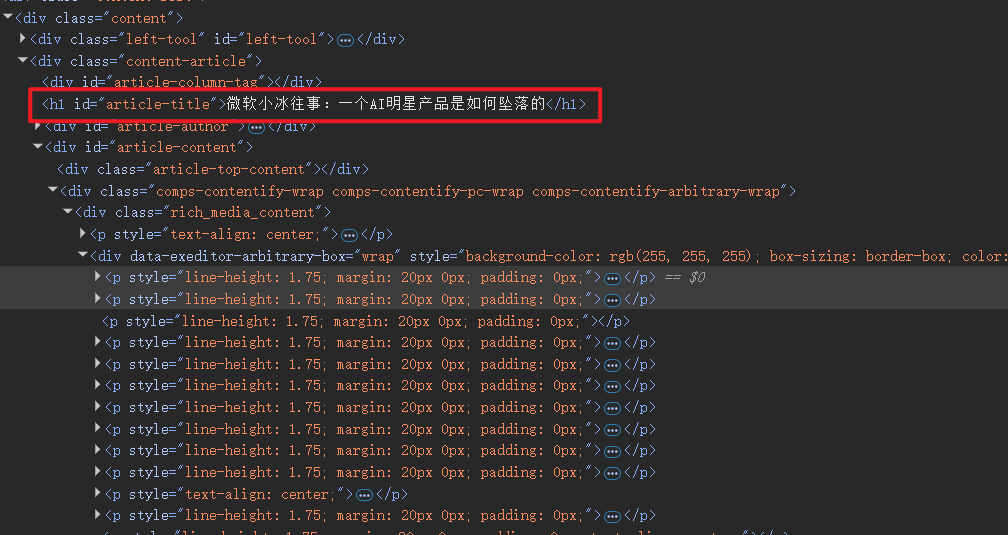
这里应该用ID选择器, 语法 "#article-title"
类选择器
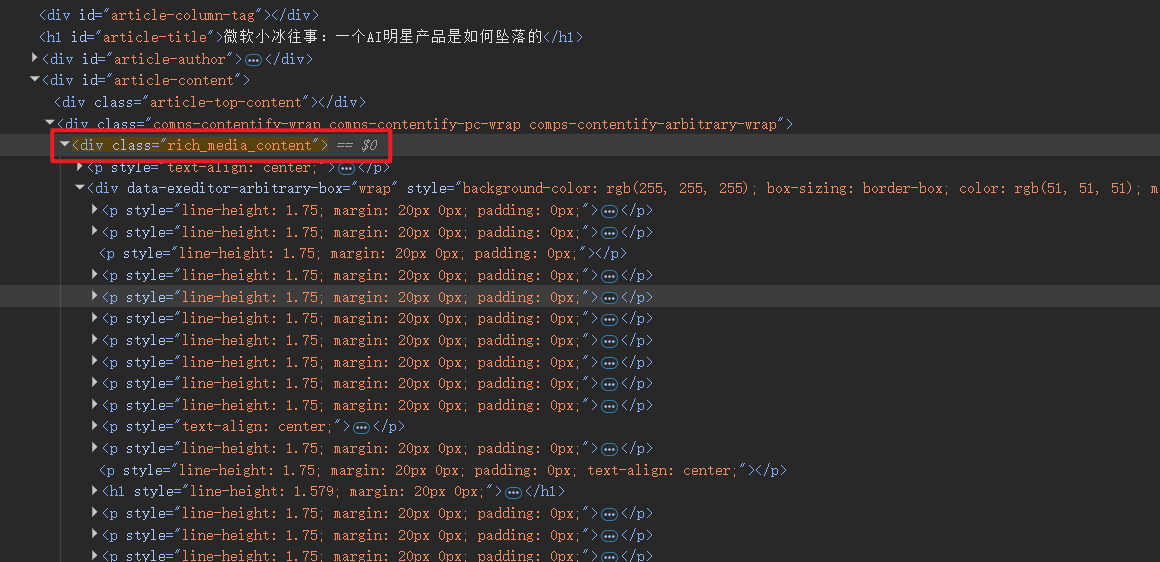
在没有ID选择器时可退而求其次, 使用类选择器, 语法 ".rich_media_content"
应该使用用于定位元素的类选择器, 而不是用于样式的选择器, 后者非常不稳定, 容易变动
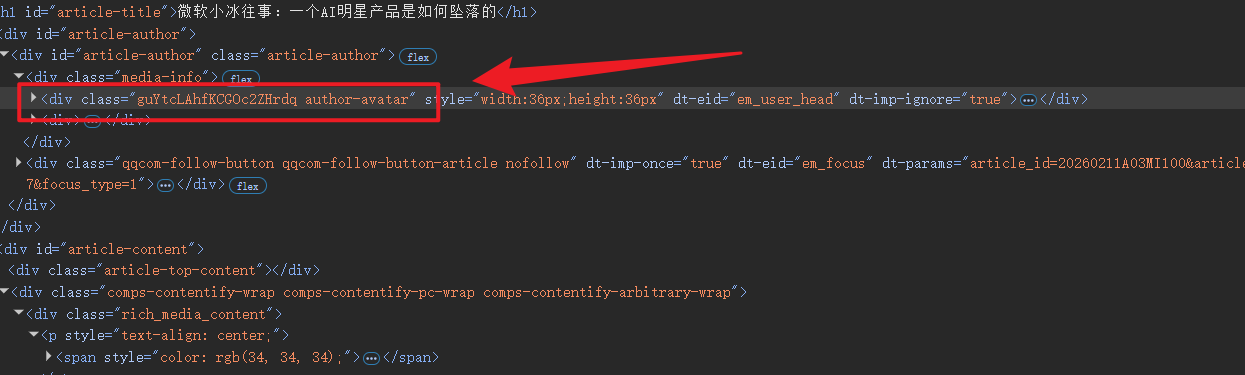
".author-avatar" 是个不错的选择器, ".guYtcLAhfKCGOc2ZHrdq" 不太适合
选择父级
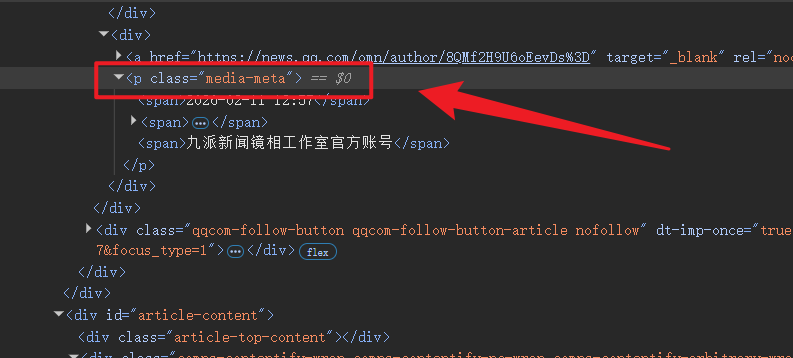
如果没有ID选择器和类选择器, 可以先选中父级元素, 通过其获取子元素, 而不是直接选择 span 元素
元素等待
因为网络请求和节点渲染需要时间, 经常会有元素未加载出来的问题, 这就需要进行等待, 下面是元素等待的要点
- 任何时候不要用
time.sleep() - 操作类的方法不需要提前等待, Playwright 有自动等待和重试的能力. 比如下面一些方法(未完全列举). 这些方法有个 timeout 参数可设置超时时间, 但是建议一般情况不用设置, 用全局超时就行.
click()fill()press()
- 获取元素文本不会自动等待和重试, 这就需要进行等待, 下面是方法对比
page.wait_for_timeout()和page.wait_for_selector(),已弃用, 不推荐expect(locator).to_be_visible(),expect()函数多用于测试, 这里不推荐locator.wait_for(), 推荐用这个方法
- *超时时间不建议在每个方法里设置, 可以通过下面方法设置
page.set_default_timeout()browser_context.set_default_timeout()
- 超时后会抛出
TimeoutError异常, 记得要用try语句捕获
事件
page.on("dialog", lambda dialog: dialog.accept())
调用 Javascript
- 运行启动脚本
// preload.js
Math.random = () => 42;
await page.add_init_script(path="./preload.js")
- 通过
evaluate()方法运行 Javascript
result = await page.evaluate("([x, y]) => Promise.resolve(x * y)", [7, 8])
print(result) # prints "56"
有用的配置
Headless
控制浏览器是否可见, 开发调试时可以设置为 False, 正式不是要设置为 True
browser = await chromium.launch(
headless=False,
)
防止 navigator.webdriver 检测
参考文档: https://juejin.cn/post/7520687447237181503#heading-4
当 Chrome 浏览器正在由自动化软件驱动时, 会将 navigator.webdriver 设置为 true, 在正常的浏览器中该值应该为 false.
绕过方法很简单, 启动 Chrome 时加一个 --disable-blink-features=AutomationControlled 开关即可
browser = await chromium.launch(
args=["--disable-blink-features=AutomationControlled"],
)
防止 viewport 检测
参考文档: https://juejin.cn/post/7520687447237181503#heading-5 当运行 Puppeteer 时, 它默认使用 800x600 的视口大小, 运行 Playwright 时, 默认使用 1280x720 的视口大小. 这个固定值非常明显, 很容易被检测到, 因为几乎没有哪个正常用户的浏览器会有这样的视口大小
# 在 context 设置
context = await browser.new_context(
viewport={"width": 1234, "height": 642}, # 只要不是 1280x720 就行
)
# 也可以页面级别设置
page = await browser.new_page(
viewport={"width": 1234, "height": 642},
)
设置 user-agent
context = await browser.new_context(
user_agent="Mozilla/5.0 (iPhone; CPU iPhone OS 17_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Mobile/15E148 Safari/604.1",
)
代理
可通过 launch() 和 new_context() 方法的参数设置
Cookies
BrowserContext 有提供 add_cookies() 方法
await browser_context.add_cookies([cookie_object1, cookie_object2])
失败处理
- 用
try捕获异常, 将错误原因记录日志 - 截屏. 因为正式环境用的无头模式, 可能出错了都不知道怎么回事, 截屏可方便排查问题
await page.screenshot(path="example.png")
- Playwright 提供 tracing 机制, 可记录这个浏览器操作过程的追踪, 但是可能比较耗性能, 正常情况下不开启
await context.tracing.start(screenshots=True, snapshots=True)
page = await context.new_page()
await page.goto("https://playwright.dev")
await context.tracing.stop(path = "trace.zip")
Docker 部署
Playwright 支持 Docker 部署, 官方有提供容器镜像, 已经预装好浏览器和相关依赖, 省去我们自己安装浏览器的繁琐.
镜像未安装 Playwright Python 包, 需要我们自己安装依赖
playwright==1.58.0
可以将整个程序打包成镜像, 下面是 Dockerfile 示例
FROM mcr.microsoft.com/playwright/python:v1.58.0-noble
WORKDIR /app
COPY requirements.txt /app
RUN python -m pip install --upgrade pip && pip install -r requirements.txt
COPY . /app
CMD ["python", "main.py"]